本記事では vSphere HA (High Availability) の動作について解説します.
vSphere HA によってホストやストレージ,仮想マシンの障害が発生した場合に仮想マシンを有効なホストで再起動させることでサービスのダウンタイムを少なくすることができます.
- VMware vSphere に関するお話
- VMware vSphere – ESXi インストール
- VMware vSphere – 仮想スイッチ/ポートグループの設定
- VMware vSphere – NFSデータストアの追加
- VMware vSphere – vCenter Server のインストール
- VMware vSphere – vCenter Server の初期設定
- VMware vSphere – ローカルデータストアの追加
- VMware vSphere – EVC (Enhanced vMotion Compatibility)
- VMware vSphere – 分散仮想スイッチ (分散仮想スイッチの説明,作成)
- VMware vSphere – 分散仮想スイッチ (アップリンクの付け替え,VMkernel インターフェイスの移行)
- VMware vSphere – 分散仮想スイッチ (仮想マシンポートグループの移行,アップリンクの完全付け替え)
- VMware vSphere – iSCSI ストレージのマウント (マウントに向けた準備)
- VMware vSphere – iSCSI ストレージのマウント
- VMware vSphere – ライブマイグレーション (vMotion と Storage vMotion)
- VMware vSphere – ライブマイグレーション(vMotion) のトラブルシュート
- VMware vSphere – vSphere DRS (Distributed Resource Scheduler) 概要
- VMware vSphere – vSphere DRS 設定 (DRS 手動)
- VMware vSphere – vSphere DRS 設定 (DRS 一部自動化)
- VMware vSphere – vSphere DRS 設定 (DRS 完全自動化)
- VMware vSphere – vSphere DRS 設定 (アフィニティとアンチアフィニティ)
- VMware vSphere – vSphere DRS 設定 (ホストアフィニティ)
- VMware vSphere – vSphere HA の説明
- VMware vSphere – vSphere HA の設定
- VMware vSphere – vSphere HA の障害時動作の確認
- VMware vSphere – vCenter Server Appliance のアップデート・アップグレード
- VMware vSphere – ESXi のアップデート・アップグレード – Life Cycle Manager 経由
- VMware vSphere – ESXi のアップデート・アップグレード – CD-ROM 経由
vSphere HA (High Availability) とは
vSphere HA は ESXi ホストに何らかの問題 (障害) が発生して正常に動作できない状態となった際,クラスター内の他の正常な ESXi ホストに仮想マシンを移動して再起動 (パワーオン) させて再稼働させる仕組みです.
仮想マシンによるサービスを提供している中,vSphere HA が無い場合は ESXi ホスト障害 = サービス障害となってしまいますが,この機能を用いることで他のホストでサービスを再提供できるようになり,サービスダウンタイムを小さくできます.
設定次第では ESXi ホストの障害ではなく,仮想マシン (OS) のハングアップでも vSphere HA による再起動を促してサービスの再提供を行うようにすることもできます.
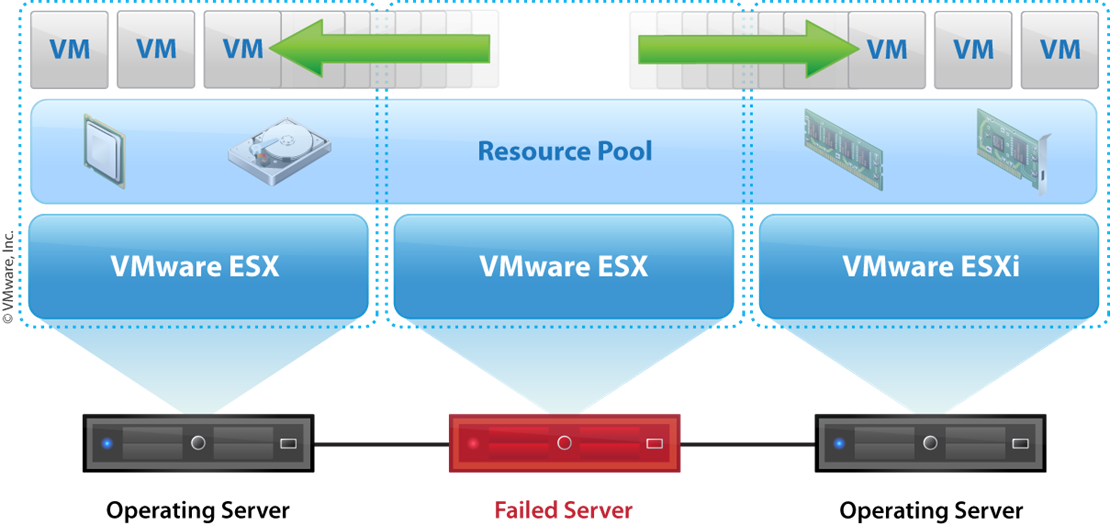
この例では真ん中の ESXi ホストに障害が発生し,左右のホストに仮想マシンが移動したことをあらわしています.
ただし,注意していただきたいのは仮想マシンは「一度シャットダウンされる」点は理解しておきましょう.
vSphere HA の動作詳細
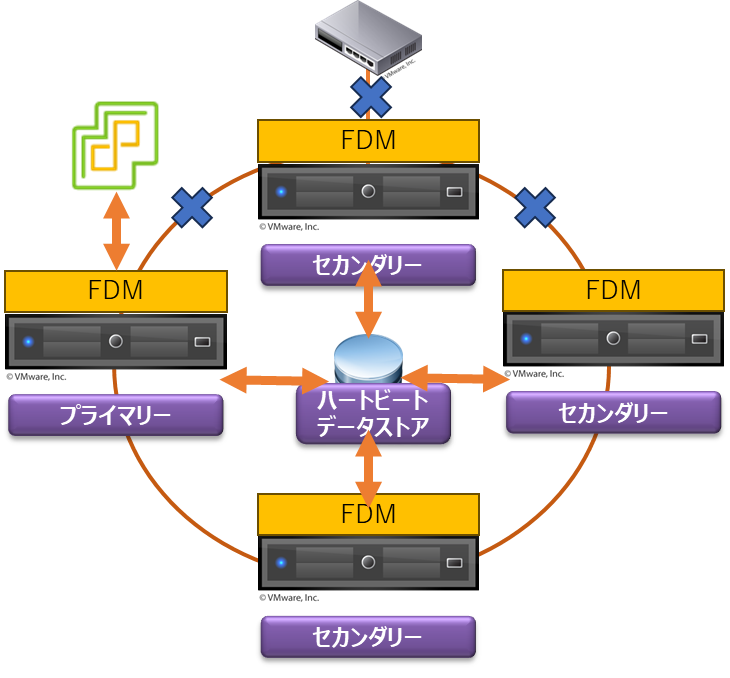
vSphere HA は,各 ESXi ホスト上で稼働する Failt Domain Manager (FDM) Agent によって機能が提供されます.
FDM はサーバーの死活を監視するため,クラスターに1台のマスターノード,それ以外のスレーブノードの間でハートビートが実行されます.このハートビートが途切れたことをトリガーに vSphere HA による仮想マシンの再起動などの動作に移ります.
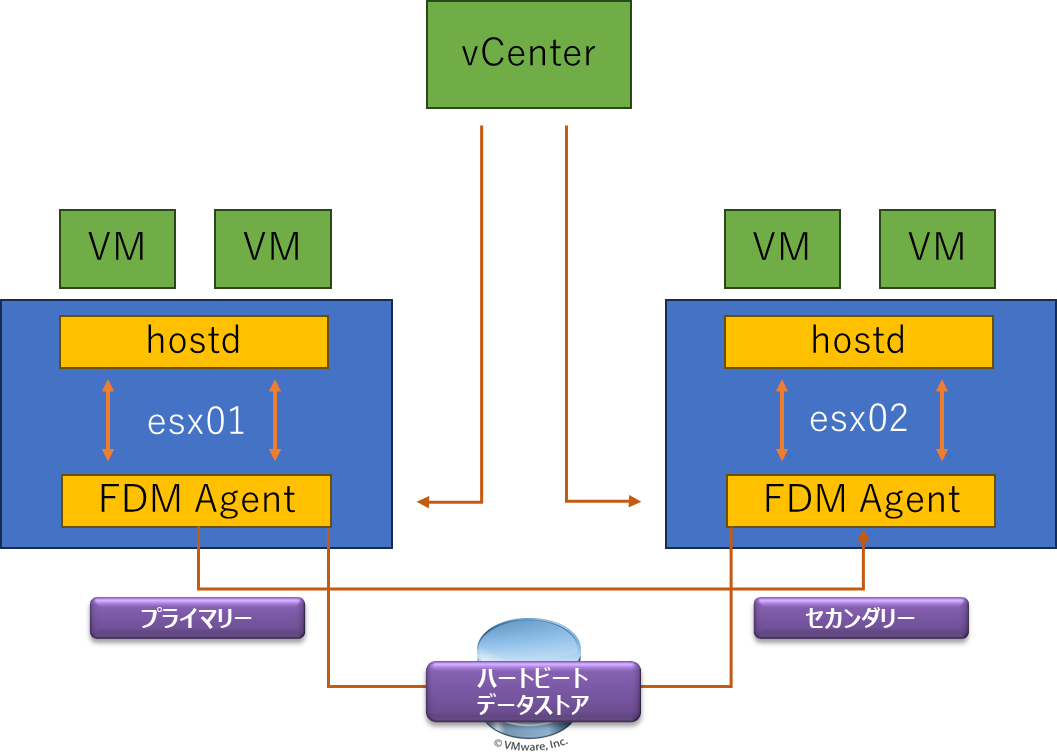
図に幾つかコンポーネントを記載していますのでそれぞれのコンポーネントについて説明します.
- FDM (Fault Domain Manager)
FDM は vSphere HA を構成する上で最も重要な機能で,HA エージェントと呼ばれます.
クラスター内の ESXi ホストのリソース状態,仮想マシンの状態などを FDM エージェント間で交換したり,ハートビートによる死活監視を行う役目を持っています.
先にも述べたとおり,HA 発動の条件判定および仮想マシンの再起動の動作も行います. - hostd
vSphere HA に関係なく ESXi ホストで重要なエージェントが hostd です.仮想マシンのパワーオン・パワーオフなどの仮想マシンを管理する役割を持っています. - vCenter Server
vSphere HA の観点での説明に留めます.vSphere クラスターの重要なコンポーネントであり,あらゆるタスクの管理を行っているのが vCenter Server です.
vCenter Server が担っている役割に次のものがあります.
・HA エージェントのデプロイや構築
・クラスター構成を変更するときの通信
・仮想マシンの保護
vCenter Server は vSphere HA の機能が有効になったら FDM エージェントを ESXi ホストに導入する役割も担っています.また,vCenter Server はクラスター内の ESXi ホスト群のうちプライマリーノード,セカンダリーノードを選ぶ決定権も持っています.
HA クラスターを構成する各 ESXi ホストの役割
上で軽く触れていますが vSphere HA はプライマリー/セカンダリーの構成になっています.
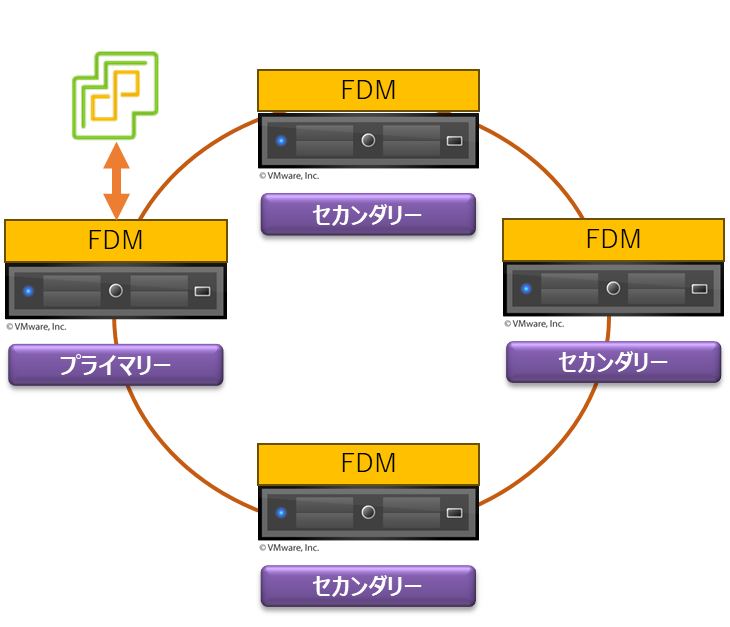
プライマリーホストは次の役割を担います.
- すべてのセカンダリーホストを監視,障害が発生した場合は仮想マシンをフェイルオーバーさせます
- 仮想マシンの状態を VMware Tools で監視,障害が発生した場合は仮想マシンをリセットします
- 保護対象の仮想マシンのリストを管理します.仮想マシンのパワーオン/パワーオフの際にリストを更新します
- セカンダリーホストとハートビートを交換します.ハートビートはプライマリーとセカンダリー間で Point to Point で通信が行われます
- HA クラスターの構成管理を行います.構成に変更が発生した際はセカンダリーに通知します
セカンダリーホストは次の役割を担います.
- 自ホストで動作している仮想マシンの状態を監視します.仮想マシンのステータスが変化した際にプライマリーホストへ通知を行います
- プライマリーホストを監視します.プライマリーホストが障害となった場合やネットワークの分断が発生した場合,セカンダリーホストの中からプライマリーホストを選出します
ハートビートネットワークとハートビートデータストア
vSphere HA はネットワーク経由のハートビートとデータストア経由のハートビートの2つを使用して HA クラスターの監視を行います.

ネットワークが切断された場合でも,データストアへのアクセスができる場合はハートビートデータストアにある情報を利用して障害の状態を正確に判断することができます.
ハートビートデータストアは,ネットワークハートビートが利用できなくなった場合のみホスト障害なのかネットワーク障害なのかを識別するために使用されます.
vSphere HA の遷移
ネットワークとデータストアの2つのハートビートを用いることでホスト障害なのか,ネットワーク障害なのかの識別が可能になり,精度の高い障害ポイントの検出とフェイルオーバー動作が可能となりました.
以下のフローチャートのとおり vSphere HA は障害を識別します.
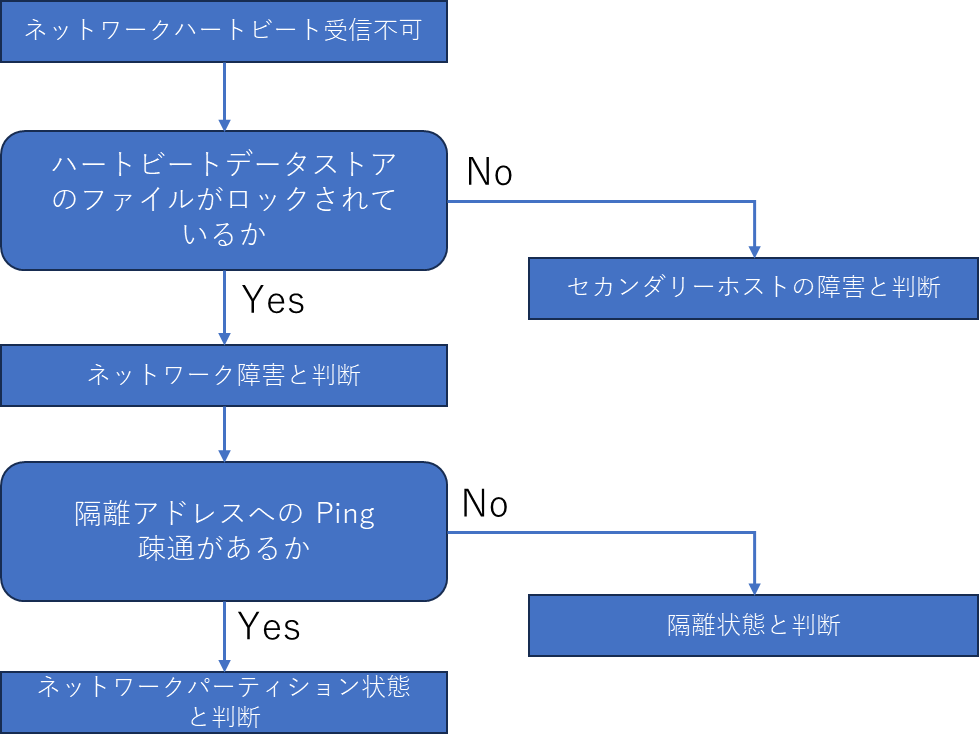
隔離アドレスへの Ping がとおるか.については,プライマリーとセカンダリーの間のハートビートネットワークの疎通が失われ,ネットワーク障害と判断された際にネットワーク隔離なのか,ネットワークパーティションなのかを識別するために使用されます.
デフォルトでは,ESXiホストの管理ネットワークのデフォルトゲートウェイアドレスが隔離アドレスとして使用されます.
隔離アドレスを追加することで,より正確な判断を行うことが可能です.
vSphere HA 発動時の動作
障害が発生し,vSphere HA によるリカバリーを行う必要が生じた際について説明します.
ホスト障害時のリカバリー動作
セカンダリーホストに障害が発生したと判断された場合,障害ホストで動作している仮想マシンを他のホストで再起動させます.
プライマリーホストに障害が発生したと判断された場合は,仮想マシンを他のホストで再起動を行うのですが,その前に正常稼働中のセカンダリーホストの中から新しいプライマリーホストの選出を行い,その後に仮想マシンの再起動を試みます.
そのため,vSphere HA による仮想マシンの再起動はホストの役割によって再起動が開始されるタイミングが違う点を認識しておく必要があります.
ホスト隔離時のリカバリー動作
ホスト隔離状態とは,プライマリーとの通信だけではなく,障害ホストから隔離アドレスへの疎通も取れずに孤立した状態を指します.
このような状態の場合,該当ホストの NIC もしくはスイッチに障害が発生している状態と考えられます.
このような状態の場合,障害ホスト上の仮想マシンをフェイルオーバーさせるかどうかの判断が難しい状態です.障害は物理ホスト側で仮想マシンとしては正常に動作している可能性があるためとなります.
仮想マシンが利用する NIC が管理用ネットワークとは違う場合,仮想マシンは正常に利用できているかもしれません.
仮想マシンが利用する NIC が管理用ネットワークと同じ場合は障害が発生しているかもしれません.
そのため,vSphere HA では「ホスト隔離への対応」を行うためのオプションが用意されています.
ホスト隔離の際の動作として以下があります
- 無効化
ホストが隔離された場合でも仮想マシンはそのままそのホスト上で稼働します - 仮想マシンをシャットダウンして再起動
ホスト隔離が検出された場合,仮想マシンをシャットダウンして他のホスト上で起動させます.
シャットダウンを行うためには VMware Tools が必要になります - 仮想マシンをパワーオフして再起動
ホスト隔離が検出された場合,仮想マシンをパワーオフして他のホスト上で起動させます
データストア障害時のリカバリー動作
データストアに障害が発生した場合も vSphere HA によるフェイルオーバーを行うことが可能です.
ただし,ストレージの障害は2つのパターンがあり,パターンによって動作が異なります.
- PDL (Permanent Device Loss) – ストレージの接続が永続的に失われた状態
データストアが削除された場合や IO が即失敗するような状態 - APD (All Path Down) – ストレージの接続が一時的に失われた状態
NFS アクセスの経路が無くなったような状態
いずれの障害の場合も利用できるオプションは次のとおりです.
- 無効化
PDL および APD が発生しても何も行いません - イベントの発行
PDL および APD が発生したら vCenter Server へイベントが通知されます.仮想マシンは自動で復旧することはありません - 仮想マシンをパワーオフして再起動
PDL および APD が発生したら仮想マシンをパワーオフし他のホストで起動します
なお「仮想マシンをパワーオフして再起動」において,APD の場合はさらに追加のオプションがあります.
- 標準的
他のホストで再起動ができると判断でいた場合のみ作動する - アグレッシブ
他のホストで再起動ができると判断できなくても作動する
仮想マシン障害時のリカバリー動作
今まではホストの障害やデータストアの障害に起因した仮想マシンのフェイルオーバーを説明していましたが,仮想マシン単体でも障害の監視,再起動を行うことができます.
仮想マシンの監視を行う場合は VMware Tools を利用してホストと仮想マシン間でハートビートによって監視が行われます.
ハートビートが途切れるとそのホスト上で仮想マシンを再起動します.
以上,vSphere HA の解説を終わります.次回は vSphere HA の設定について説明します.
コメント