本記事では vSphere HA 構成時に障害が発生した際の挙動を幾つかのパターンで発生させてどのように動作するのかを紹介します.
デフォルトで無効な設定もありますので,有効にするのかどうか判断の材料になれば幸いです.
- VMware vSphere に関するお話
- VMware vSphere – ESXi インストール
- VMware vSphere – 仮想スイッチ/ポートグループの設定
- VMware vSphere – NFSデータストアの追加
- VMware vSphere – vCenter Server のインストール
- VMware vSphere – vCenter Server の初期設定
- VMware vSphere – ローカルデータストアの追加
- VMware vSphere – EVC (Enhanced vMotion Compatibility)
- VMware vSphere – 分散仮想スイッチ (分散仮想スイッチの説明,作成)
- VMware vSphere – 分散仮想スイッチ (アップリンクの付け替え,VMkernel インターフェイスの移行)
- VMware vSphere – 分散仮想スイッチ (仮想マシンポートグループの移行,アップリンクの完全付け替え)
- VMware vSphere – iSCSI ストレージのマウント (マウントに向けた準備)
- VMware vSphere – iSCSI ストレージのマウント
- VMware vSphere – ライブマイグレーション (vMotion と Storage vMotion)
- VMware vSphere – ライブマイグレーション(vMotion) のトラブルシュート
- VMware vSphere – vSphere DRS (Distributed Resource Scheduler) 概要
- VMware vSphere – vSphere DRS 設定 (DRS 手動)
- VMware vSphere – vSphere DRS 設定 (DRS 一部自動化)
- VMware vSphere – vSphere DRS 設定 (DRS 完全自動化)
- VMware vSphere – vSphere DRS 設定 (アフィニティとアンチアフィニティ)
- VMware vSphere – vSphere DRS 設定 (ホストアフィニティ)
- VMware vSphere – vSphere HA の説明
- VMware vSphere – vSphere HA の設定
- VMware vSphere – vSphere HA の障害時動作の確認
- VMware vSphere – vCenter Server Appliance のアップデート・アップグレード
- VMware vSphere – ESXi のアップデート・アップグレード – Life Cycle Manager 経由
- VMware vSphere – ESXi のアップデート・アップグレード – CD-ROM 経由
VMware vSphere – vSphere HA の障害時動作の確認
vSphere HA の動作確認 – ESXi ホストパニック時の動作
今回はデフォルト状態ですので仮想マシンの監視は行っていません.従ってホスト障害のみ vSphere HA による再起動が行われます.
ここでは,疑似的に障害を発生させて vSphere HA の動作を確認する方法を紹介します.
まずは障害を発生させるホストを確認します.今回は「esxi02.lab.seichan.org」を対象にします.
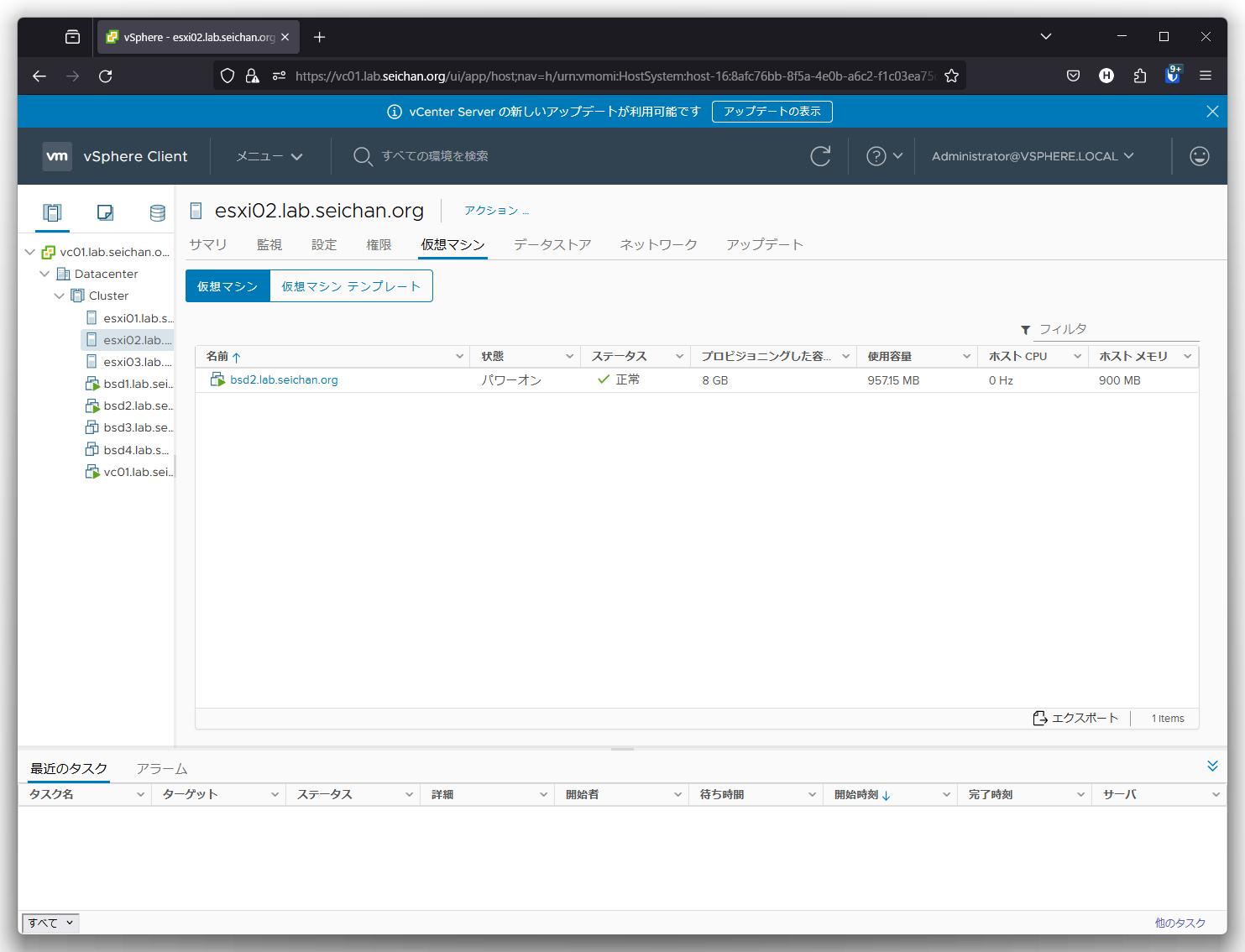
対象のホストの SSH もしくは Shell に入り,次のコマンドを実行します.
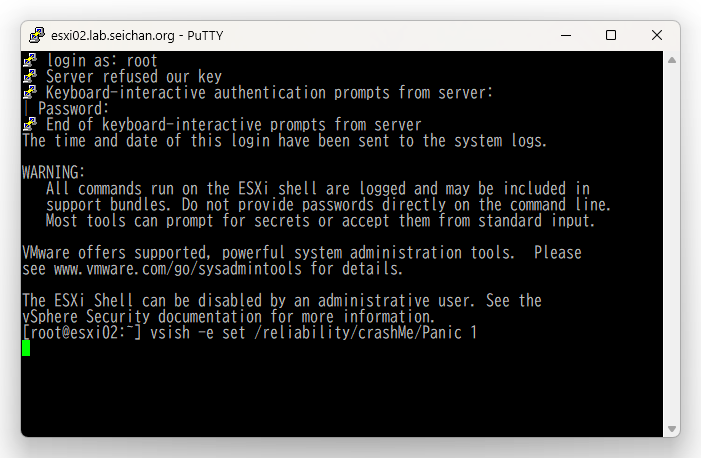
コマンドを実行すると ESXi ホストは PSOD (purple screen of death) 状態となり,紫のエラー画面に変わります.
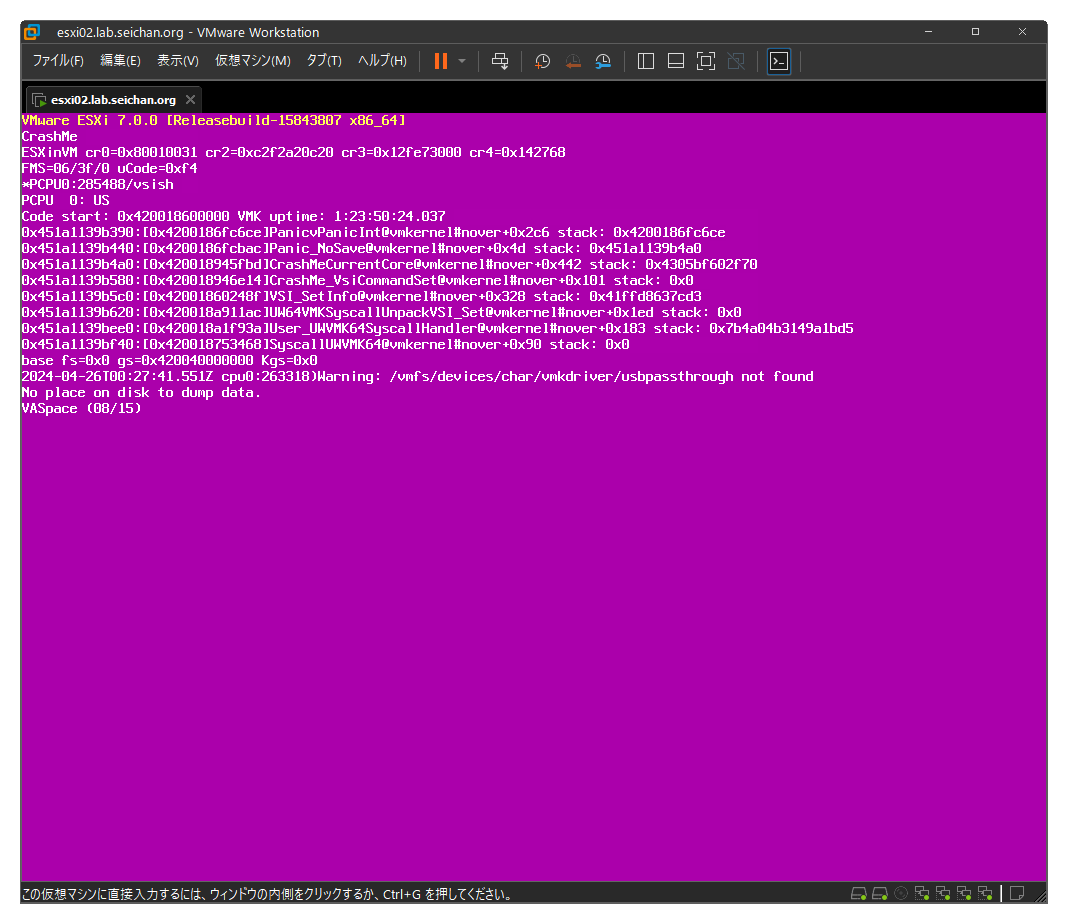
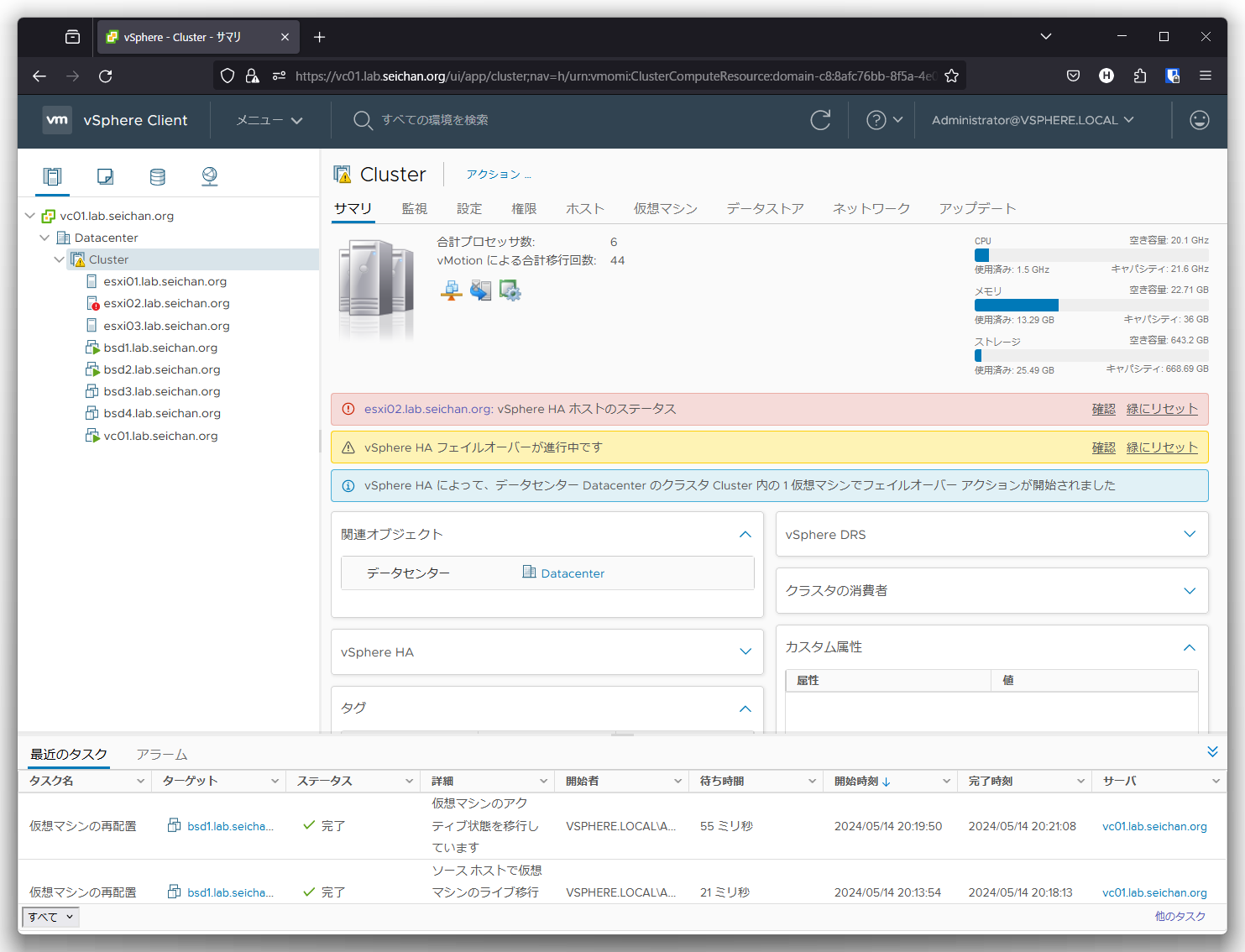
クラスターのステータスを確認すると「vSphere HA フェイルオーバーが進行中です」などの状態が表示されます.
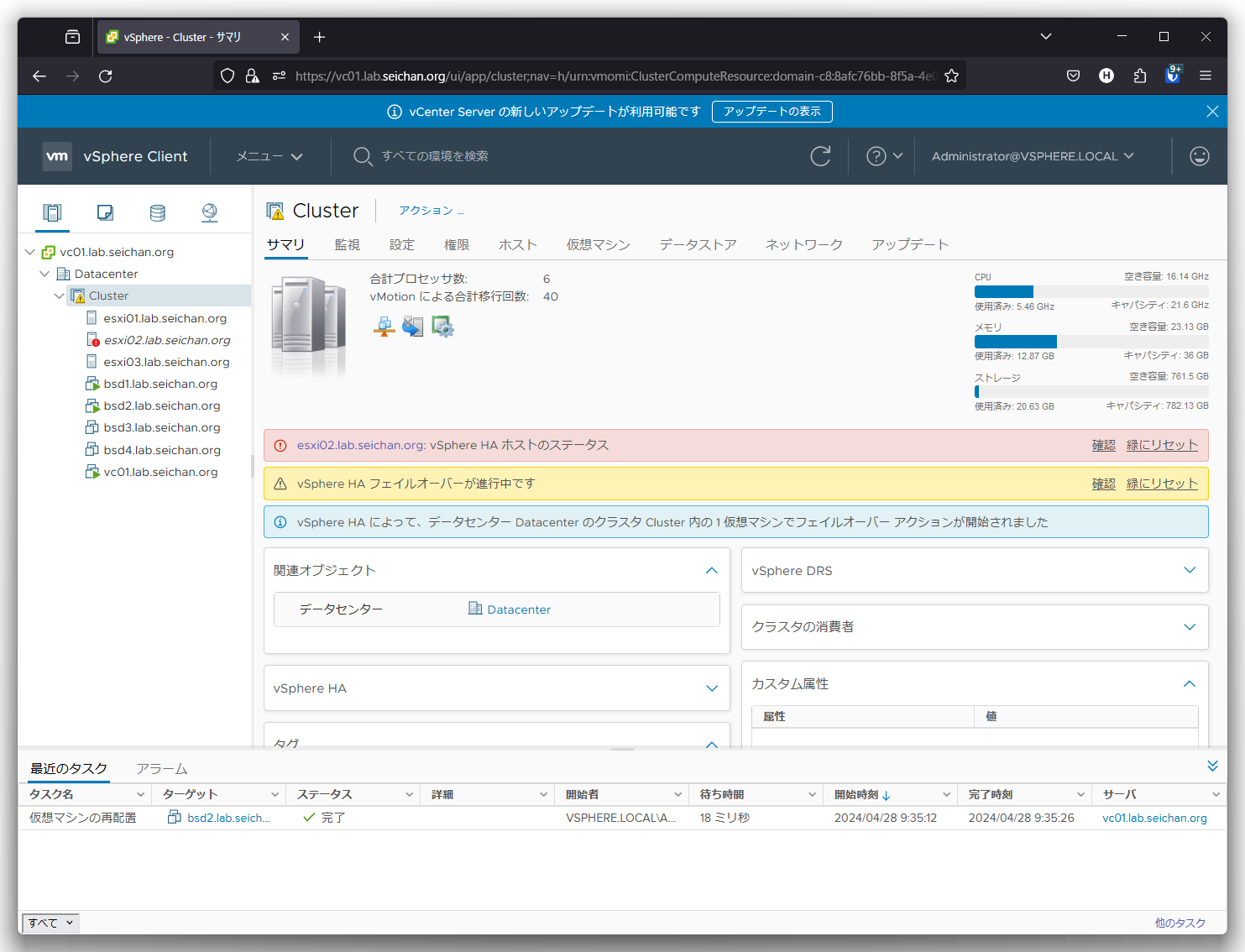
30秒~1分位 (プライマリーなのかセカンダリーなのかで発動タイミングが異なります) 経つとフェイルオーバーが開始され,正常なホストでパワーオンが行われます.
以上,疑似的にホスト障害を発生させて vSphere HA の動作を確認する方法となります.
vSphere HA の動作確認 – 仮想マシンハングアップ時の動作
VMware Tools を介した仮想マシン監視を有効にすることで仮想マシンがハングアップした際に再起動を自動的に行うことが可能になります.
「設定」-「vSphere の可用性」より vSphere HA の「編集」をクリックします.
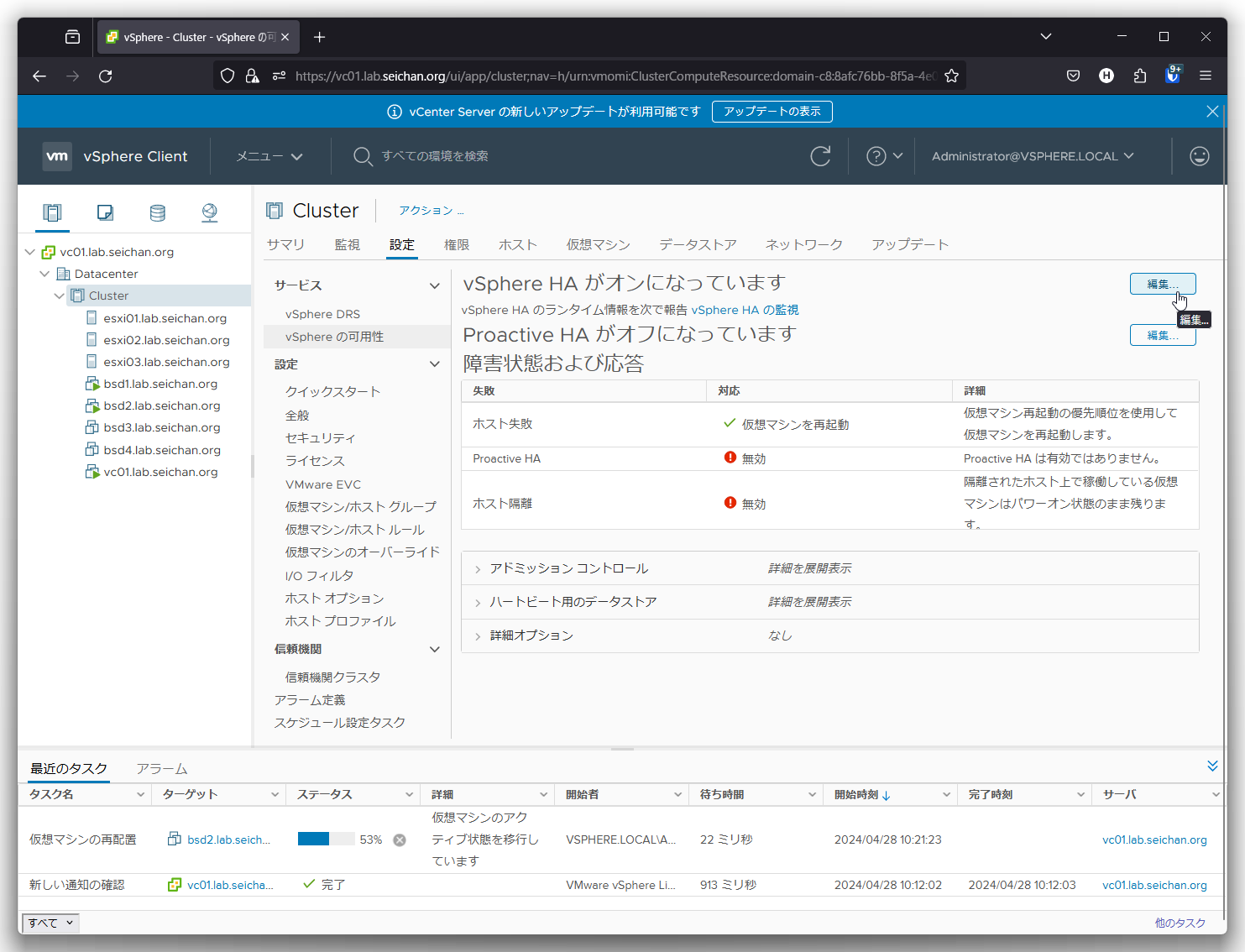
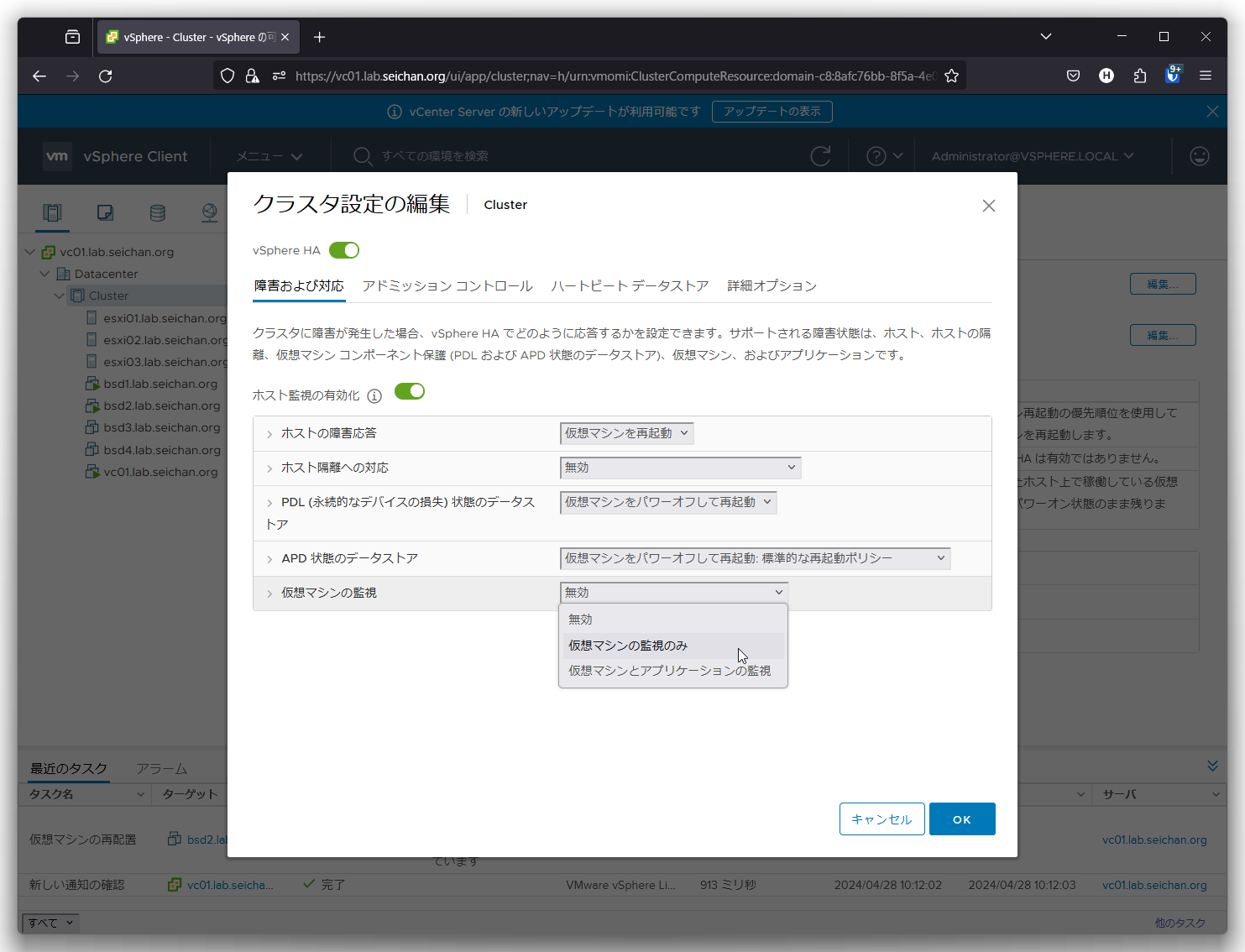
「障害及び対応」の「仮想マシンの監視」を「無効」以外に設定します.今回は「仮想マシンの監視のみ」を選択しています.
設定が完了できたら「OK」をクリックして設定を反映させます.
クラスタの再設定が完了したことを確認します.
仮想マシンをハングアップさせます.今回はディスクの切断でハングアップ状態を発生させましたが,他の方法があればそれでもかまいません.
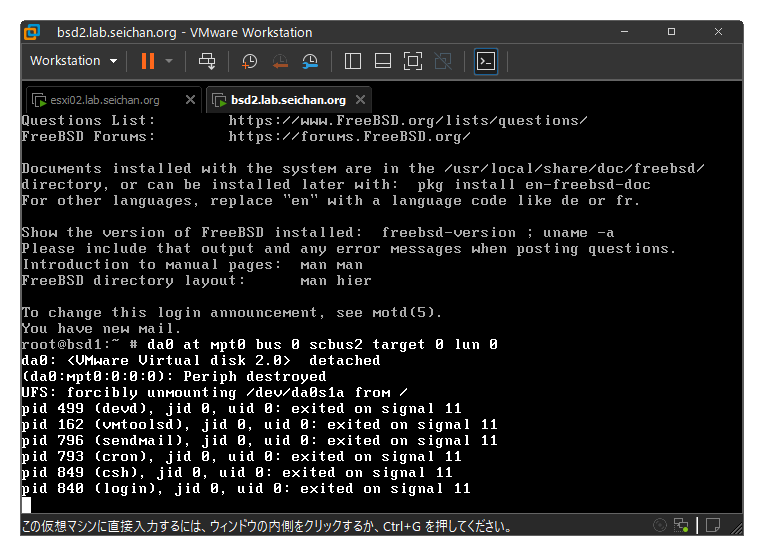
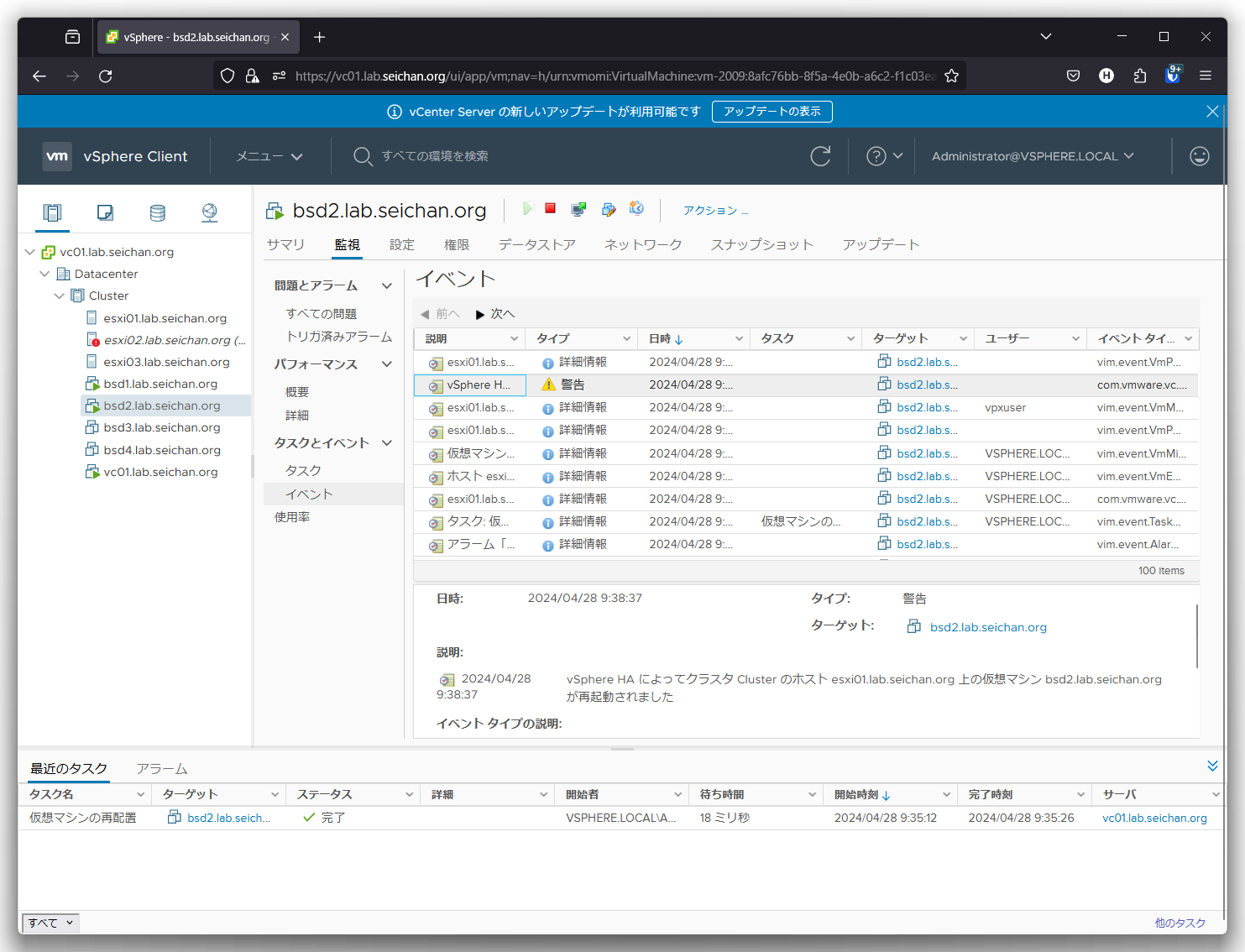
しばらくすると「vSphereHA の仮想マシンの監視アクション」アラームが発報され,再起動が開始されます.
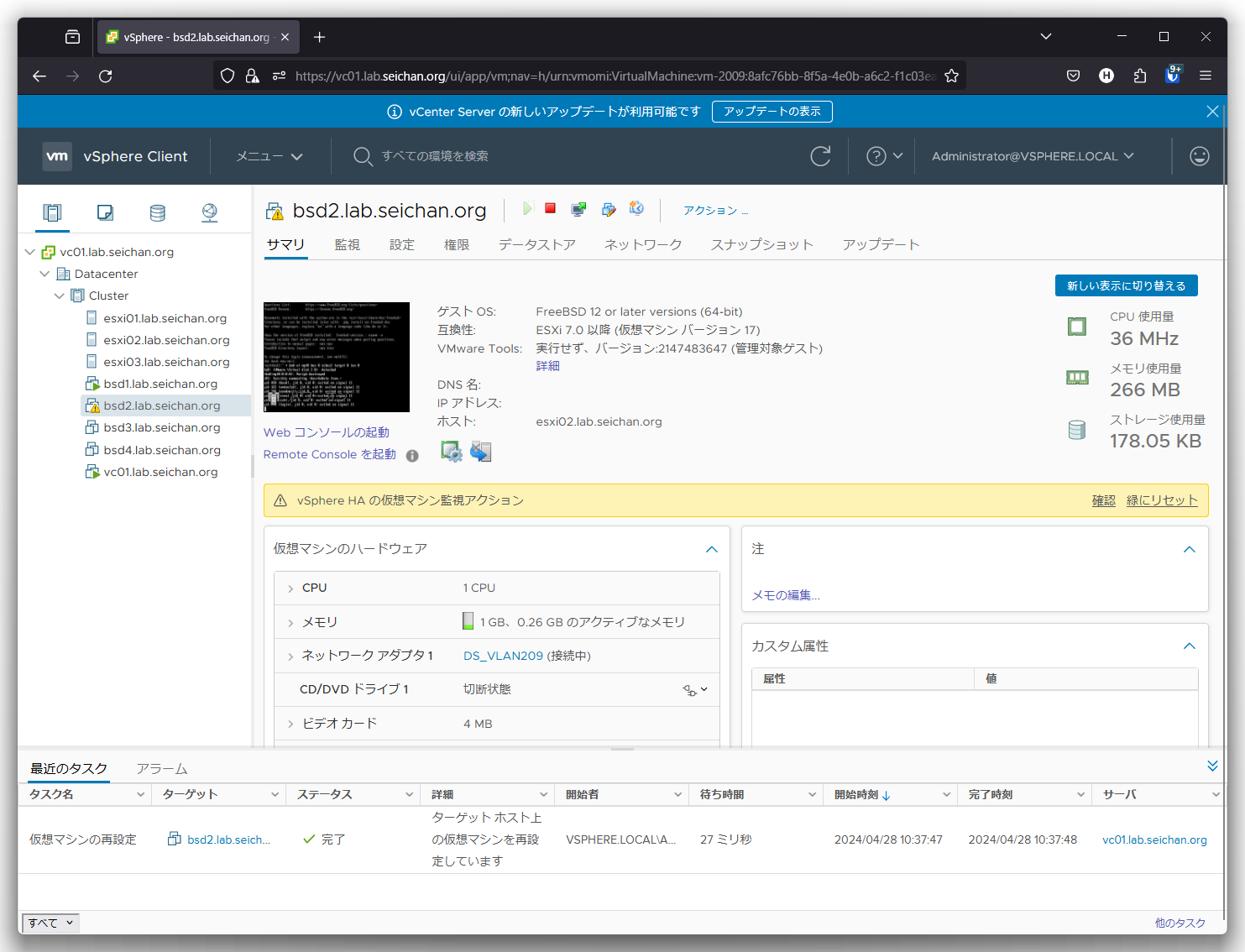
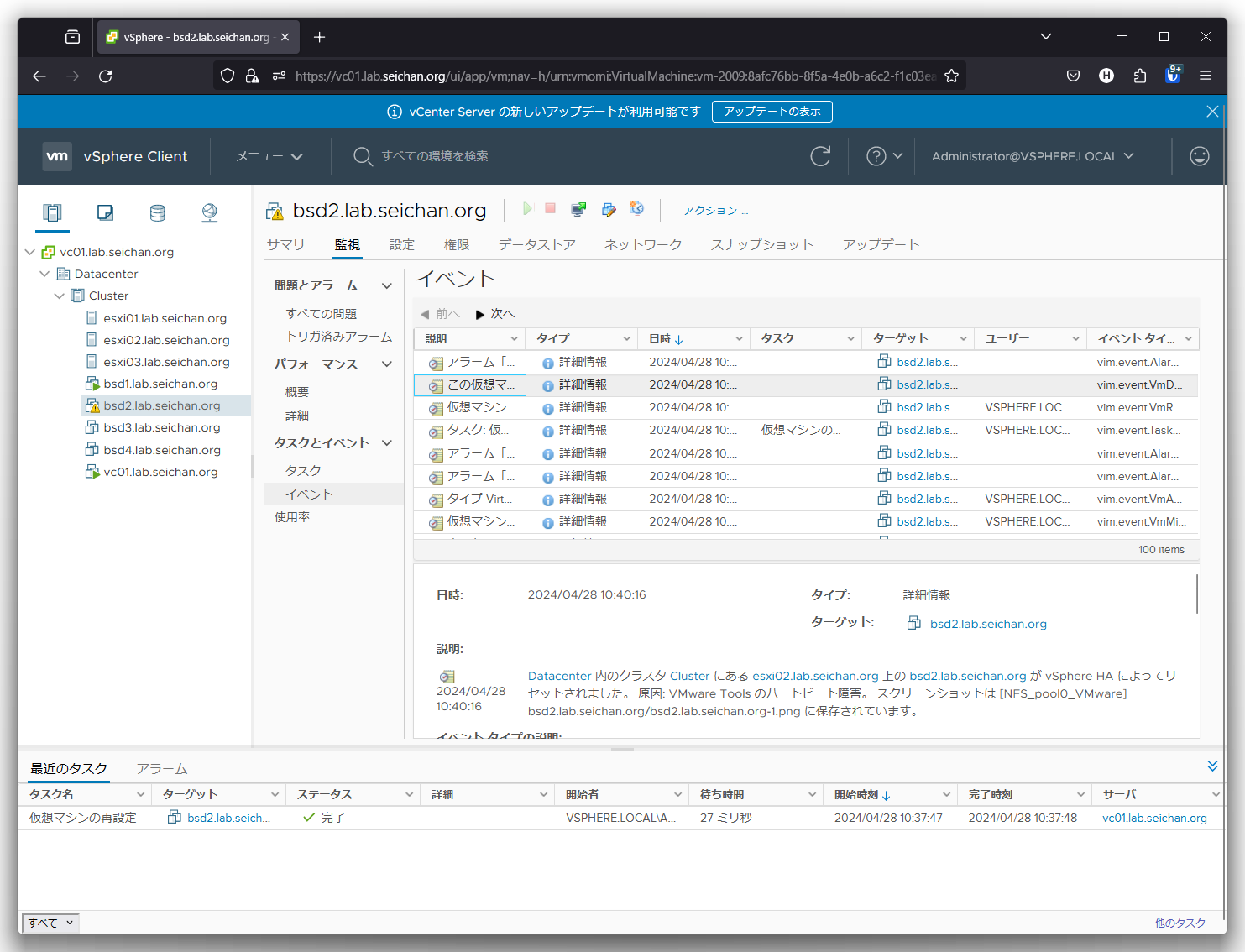
イベントを確認すると,この画面のように「vSphere HA によってリセットされました」というイベントが確認できます.
このように,仮想マシンのハングアップに対応できるため,監視の有効化を検討するのは良いアイデアです.
ただ,全体的に仮想基盤が高負荷の状態が続くと,この監視に失敗する場合がありますのでオーバーコミットが当たり前の環境で高負荷な状態が前提の基盤では予期しないリセットが発生することがあります.全体的な負荷状態も考慮に入れる必要がある点に注意してください.
vSphere HA の動作確認 – ストレージアクセス不可 (All Path Down) 時の動作
ESXi – ストレージ間に障害が発生し,APD (All Path Down) 状態になった際の挙動を確認します.
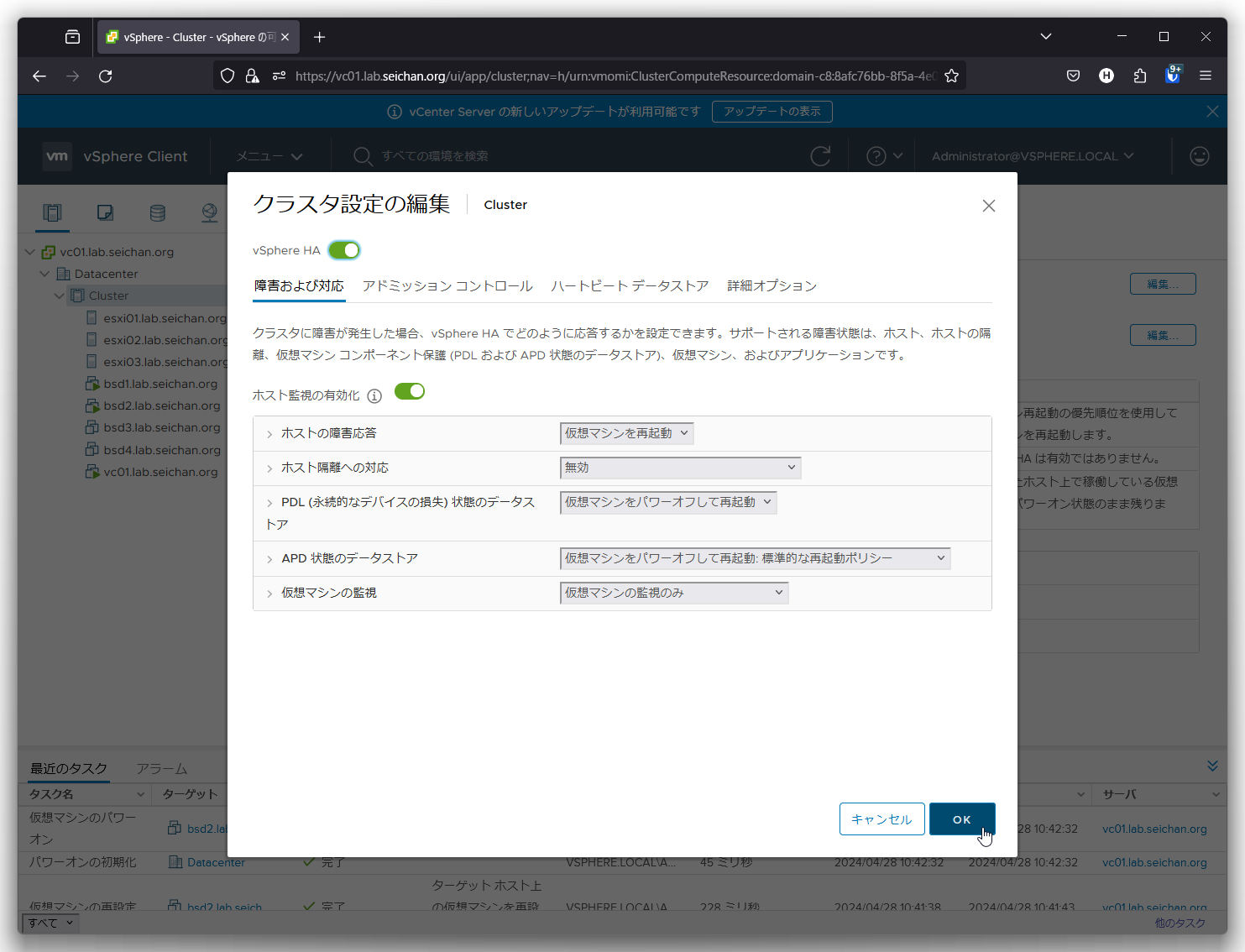
設定値の確認のため「設定」-「vSphere の可用性」より vSphere HA の「編集」をクリックします.
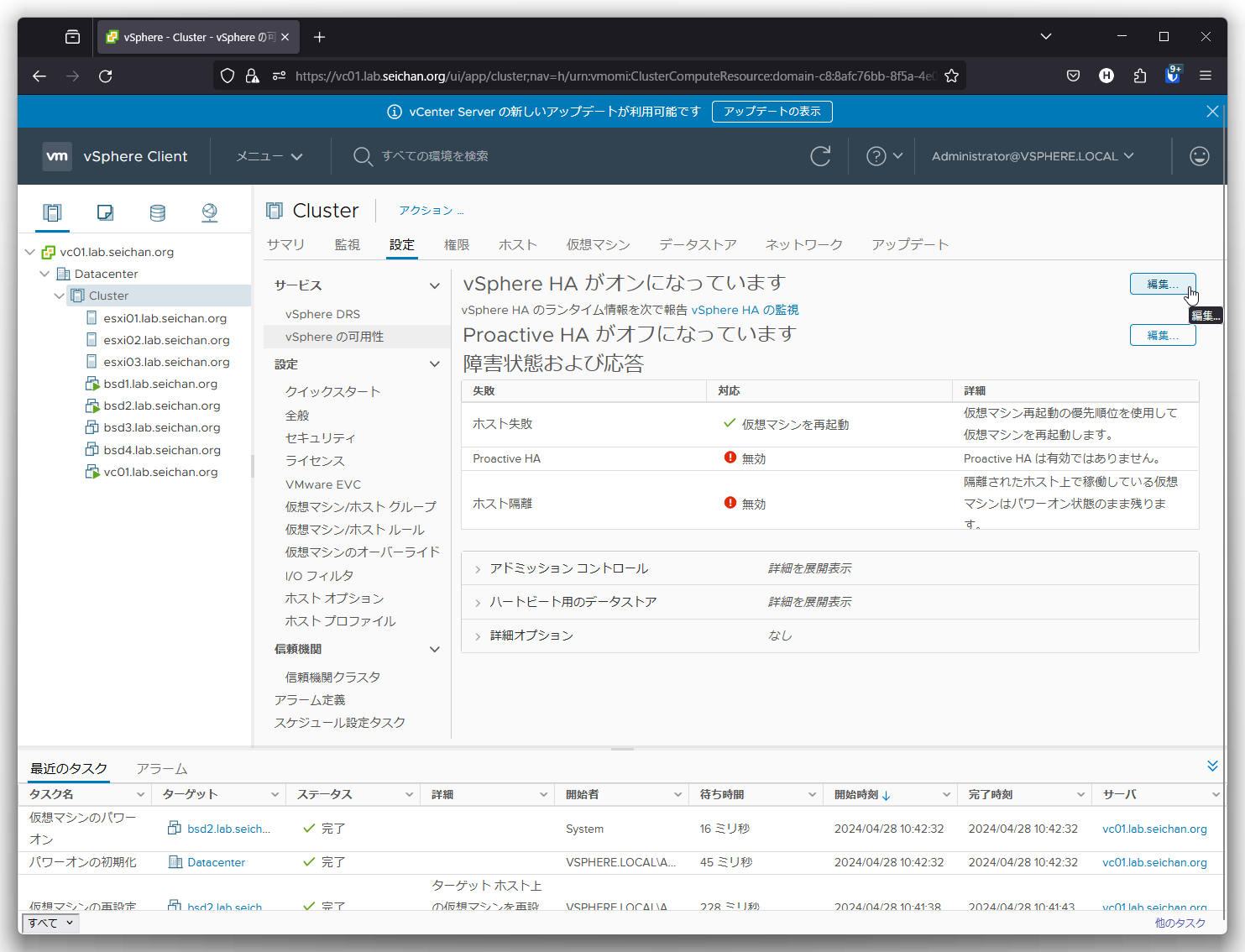
「APD状態のデータストア」の設定を確認します.デフォルトではパワーオフして再起動というポリシーになっています.
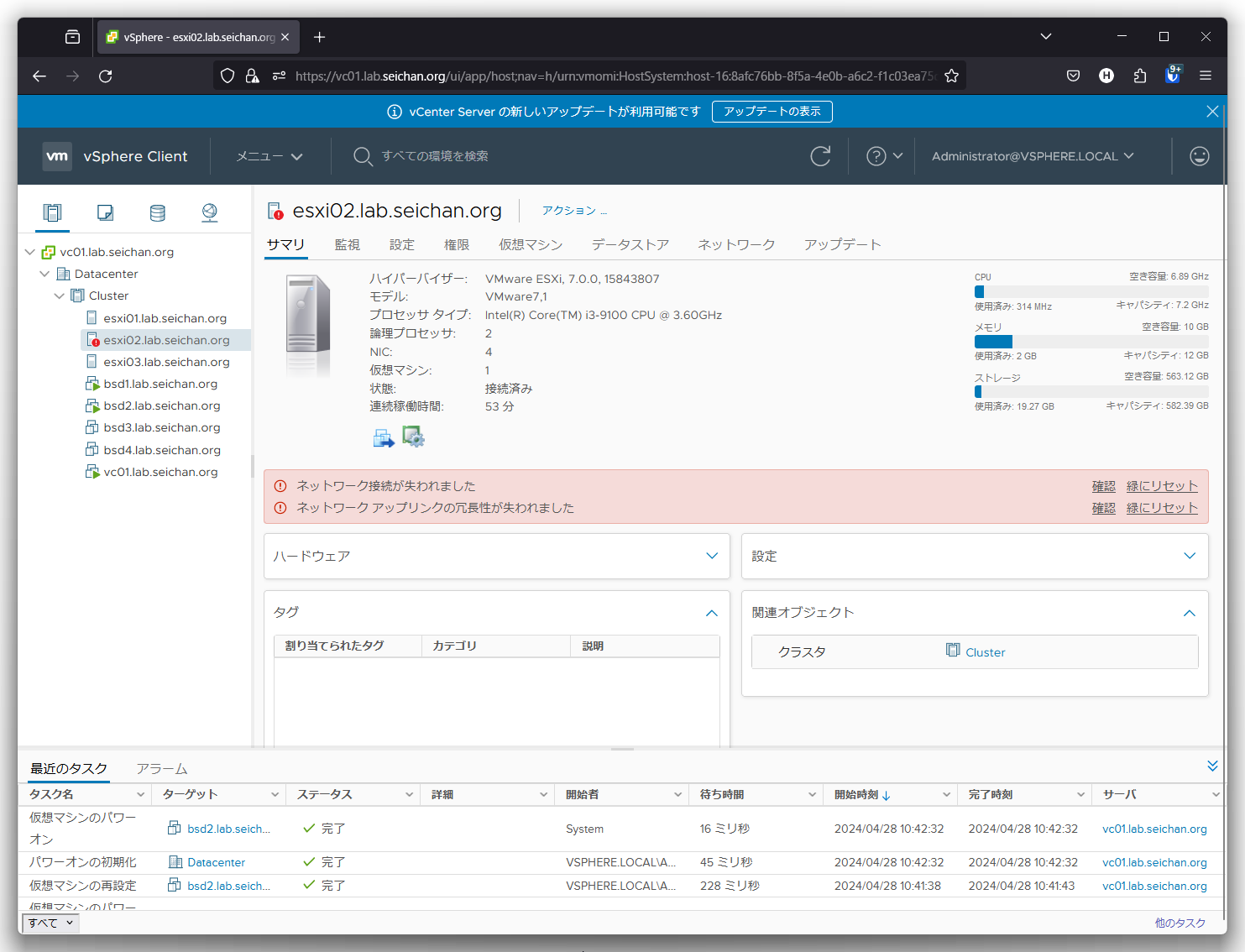
ストレージパスを切断してみます.
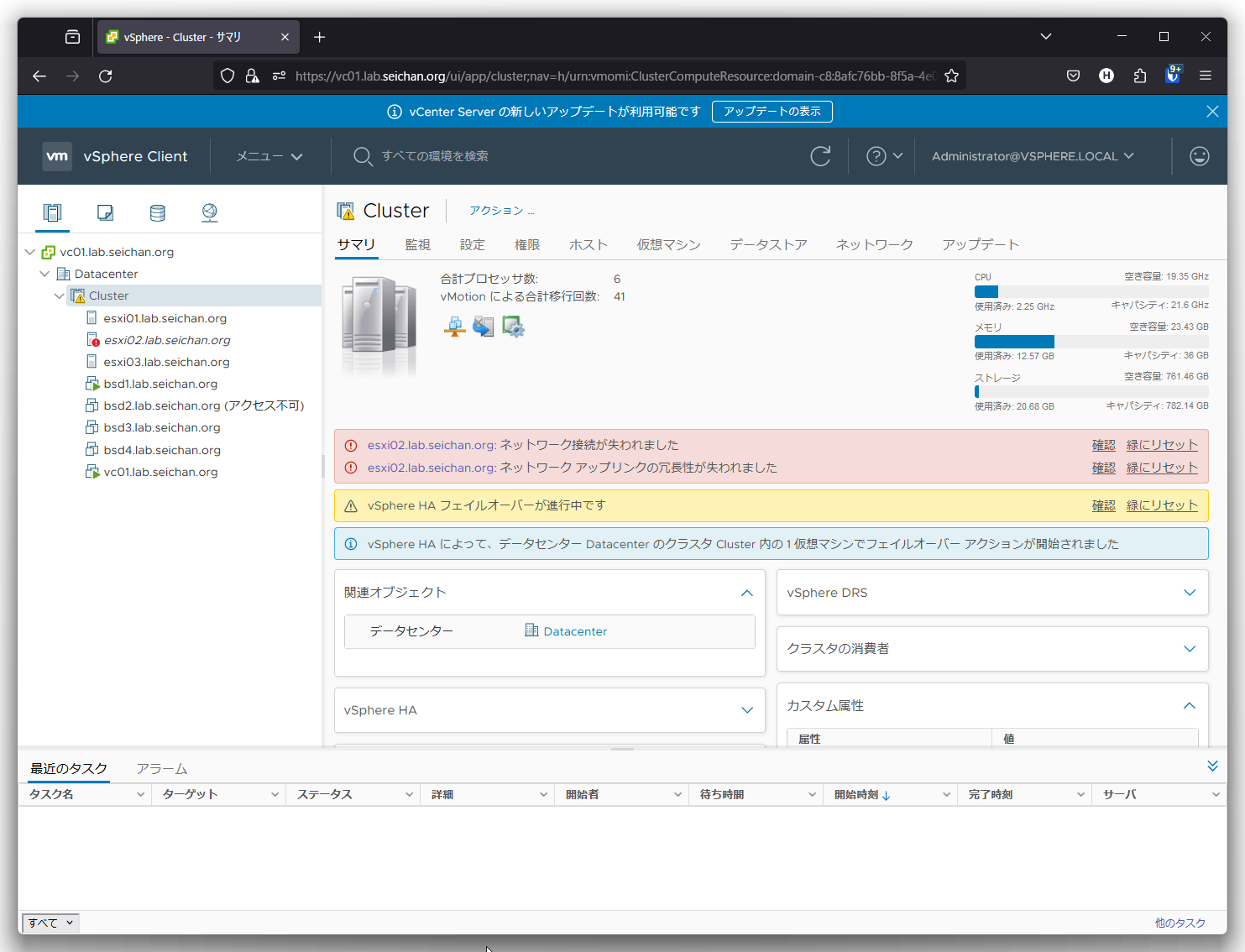
しばらくすると vSphere HA フェイルオーバーが発生した旨のメッセージが表示されます.
仮想マシンのイベントを確認すると,vSphere HA によって再起動が行われたことが確認できます.
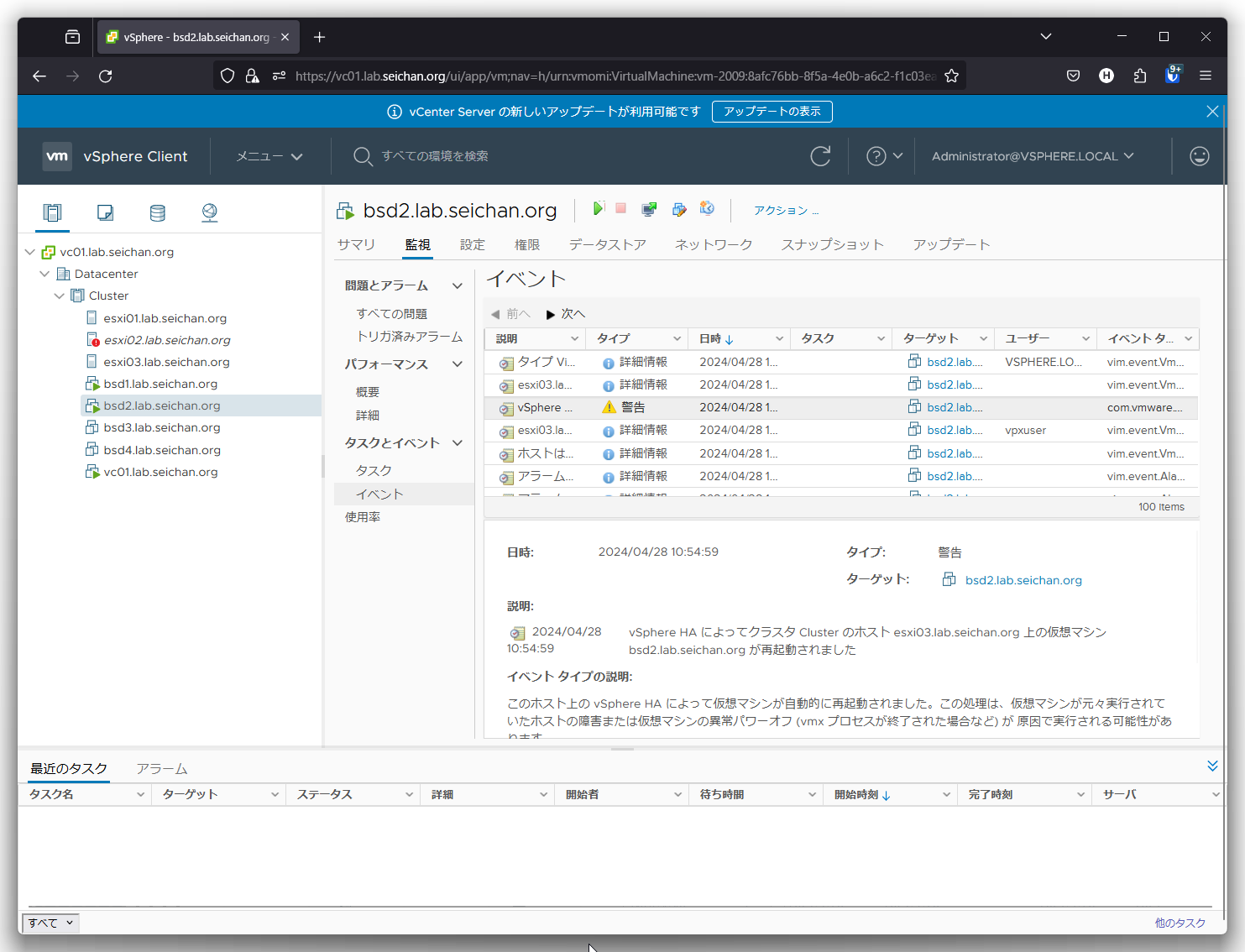
vSphere HA の動作確認 – ホスト隔離時の動作
vSphere HA 構成時,ホストがネットワークから隔離された場合に該当ホスト上の仮想マシンを別の正常なホストに移動 (再起動) させることができます.
この設定はデフォルトでは無効ですので,有効化する必要があります.
「設定」-「vSphere の可用性」より vSphere HA の「編集」をクリックします.
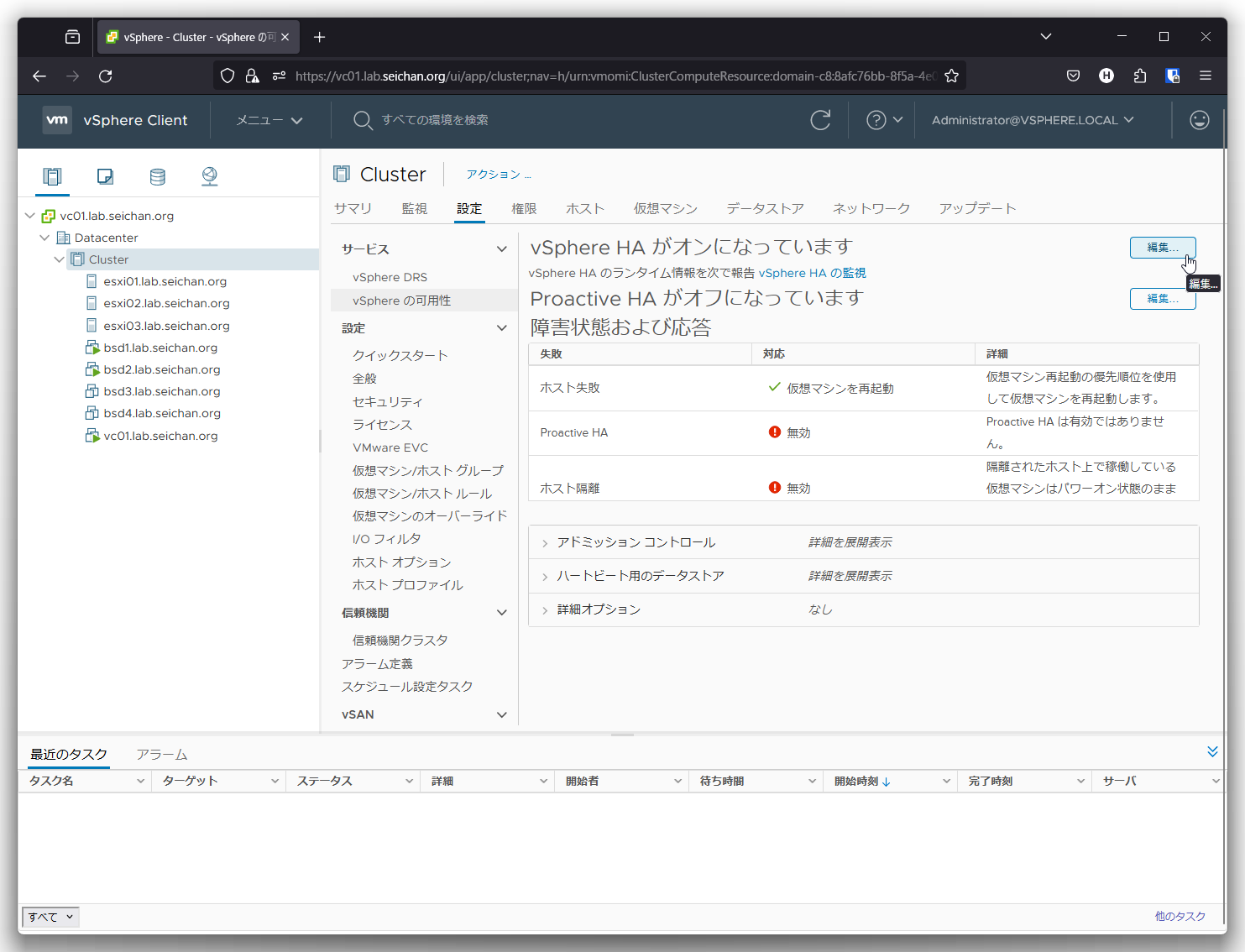
「ホスト隔離への対応」を「無効」以外を選択します.今回は「仮想マシンをシャットダウンして再起動」を選択します.
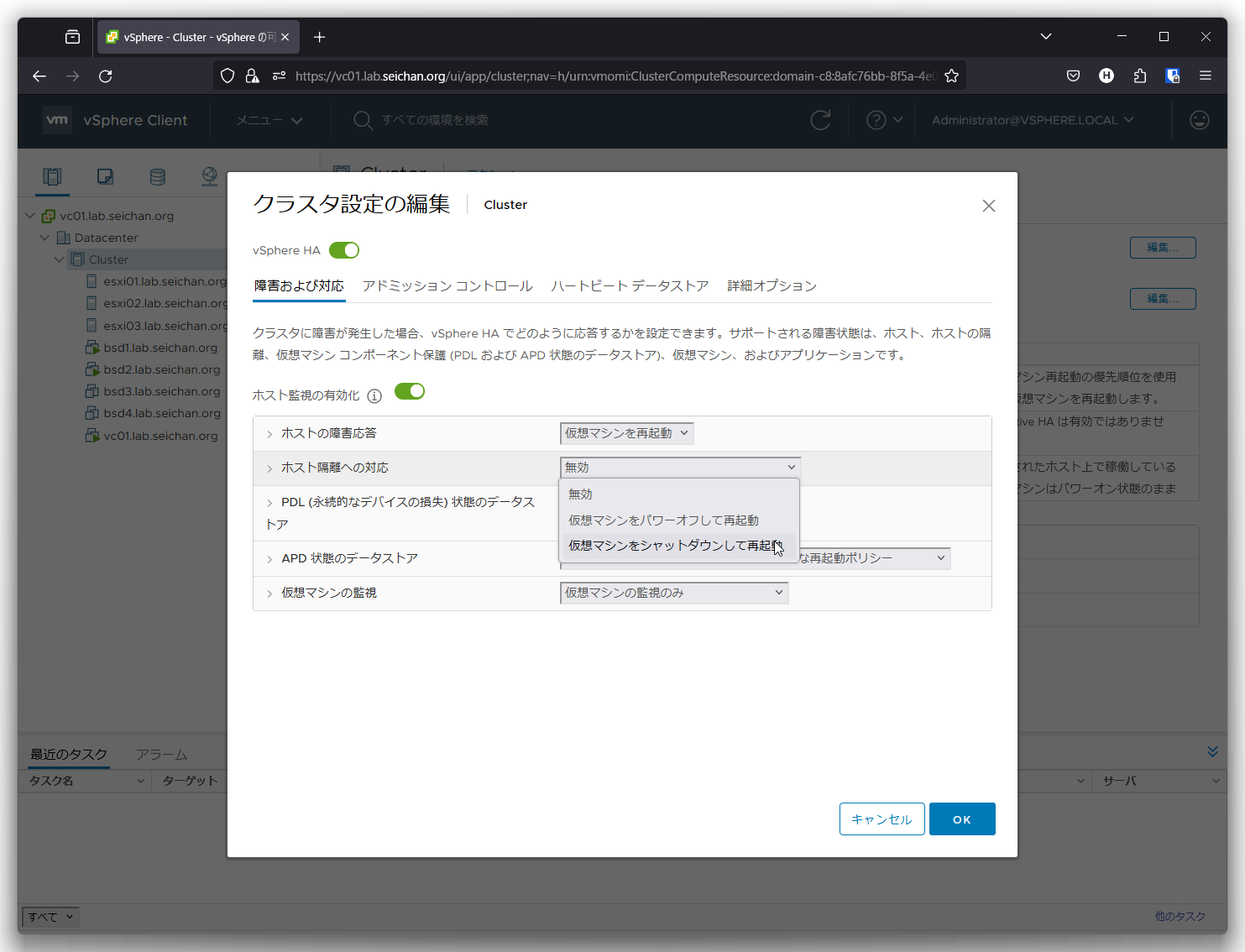
設定が行われたことを確認して「OK」をクリックします.
ESXi のアップリンクネットワークを全て切断させると,この画面のようにアラームが表示されます.
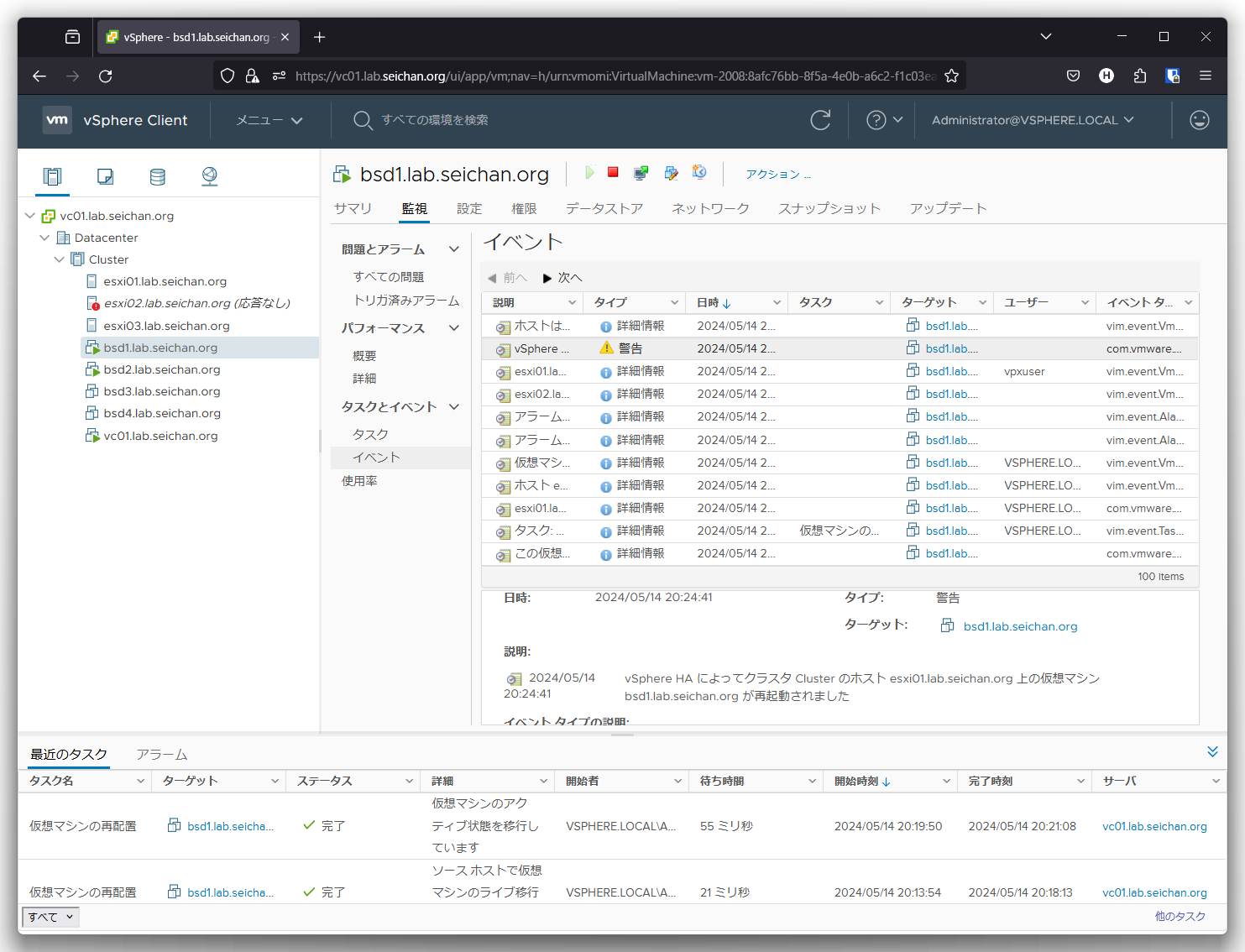
仮想マシンのイベントを確認すると,別のホストで再起動されていることが確認できます.
以上,vSphere HA のフェイルオーバー動作について幾つかのパターンを紹介しました.
次回は vSphere から離れて Windows Server によるフェイルオーバークラスターについて解説を行います.

コメント